[☸️K8s] 워크로드 리소스와 CRI: YAML이 프로세스가 되기까지
Deployment YAML이 kubelet, CRI, OCI, runc, Linux kernel primitives를 거쳐 실제 컨테이너 프로세스로 실행되는 흐름과 Pod·Workload Resource의 역할을 정리합니다.

쿠버네티스에서 deployment.yaml은 단순한 설정 파일이 아니다. image, resources, replicas, probe 같은 필드는 각각 CRI, OCI, cgroups, kubelet, Controller로 이어지는 서로 다른 레이어에 닿아 있다. 이번 글은 하나의 Deployment YAML이 kubelet과 containerd, runc, Linux kernel primitives를 거쳐 실제 프로세스가 되는 과정을 정리한다.
What this post covers
deployment.yaml의 각 필드가 실제 실행 레이어와 연결되는 방식- 컨테이너가 VM과 달리 호스트 커널을 공유할 수 있는 이유
- namespace, cgroups,
pivot_root()가 컨테이너 격리와 자원 제한을 구현하는 방식 - OCI Image Spec과 Runtime Spec이 이미지와 컨테이너 실행을 표준화하는 방식
- CRI가 kubelet과 container runtime 사이에서 Pod 단위 실행을 추상화하는 이유
- pause 컨테이너와 PodSandbox가 Pod namespace 생명주기를 유지하는 방식
- Pod의 probe, restartPolicy, QoS, lifecycle과 Workload Resource의 관계
0. Overview
지난 글에서는 쿠버네티스 리소스와 GVK 체계를 정리했다. 이번 글의 출발점은 실제로 작성하는 deployment.yaml이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
apiVersion: apps/v1
kind: Deployment
metadata:
name: jr-example
namespace: jaram
labels:
app: jr-example
app.kubernetes.io/managed-by: kubectl
app.kubernetes.io/part-of: jaram
app.kubernetes.io/component: backend
app.kubernetes.io/name: jr-example
spec:
selector:
matchLabels:
app: jr-example
replicas: 1
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
metadata:
labels:
app: jr-example
spec:
containers:
- name: jr-example
image: ghcr.io/jaram/example:latest
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 500m
memory: 1Gi
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 300
timeoutSeconds: 2
successThreshold: 1
failureThreshold: 3
periodSeconds: 10
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 120
timeoutSeconds: 5
successThreshold: 3
failureThreshold: 5
periodSeconds: 10
envFrom:
- configMapRef:
name: jr-example-config
- secretRef:
name: jr-example-secret
ports:
- containerPort: 8080
name: http
restartPolicy: Always
imagePullSecrets:
- name: ghcr-secret
이 파일이 kubectl apply -f deployment.yaml을 통해 적용되면 쿠버네티스는 선언된 상태를 클러스터의 실제 상태와 일치시키기 시작한다.
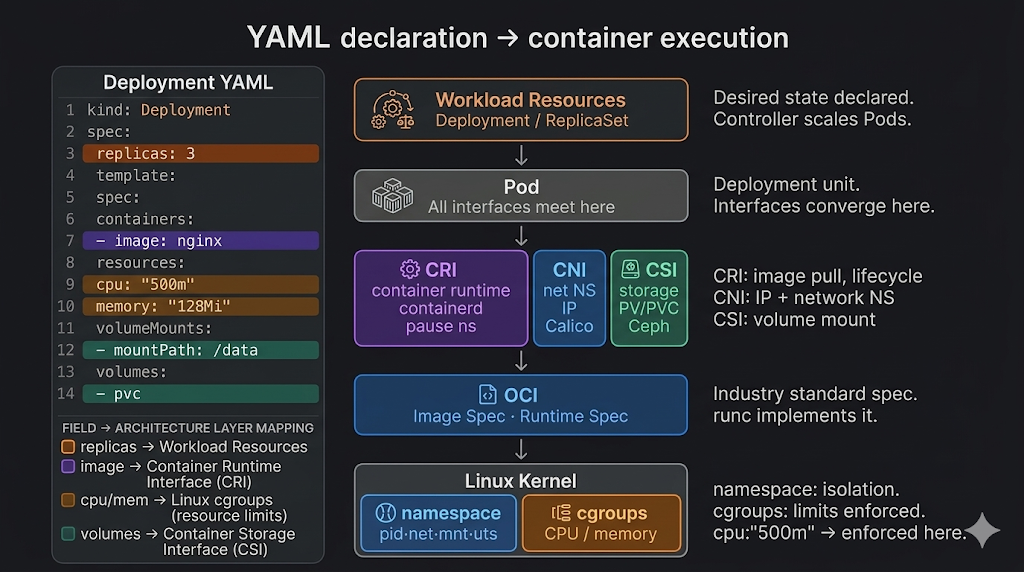
0.1 지난 흐름 되짚기
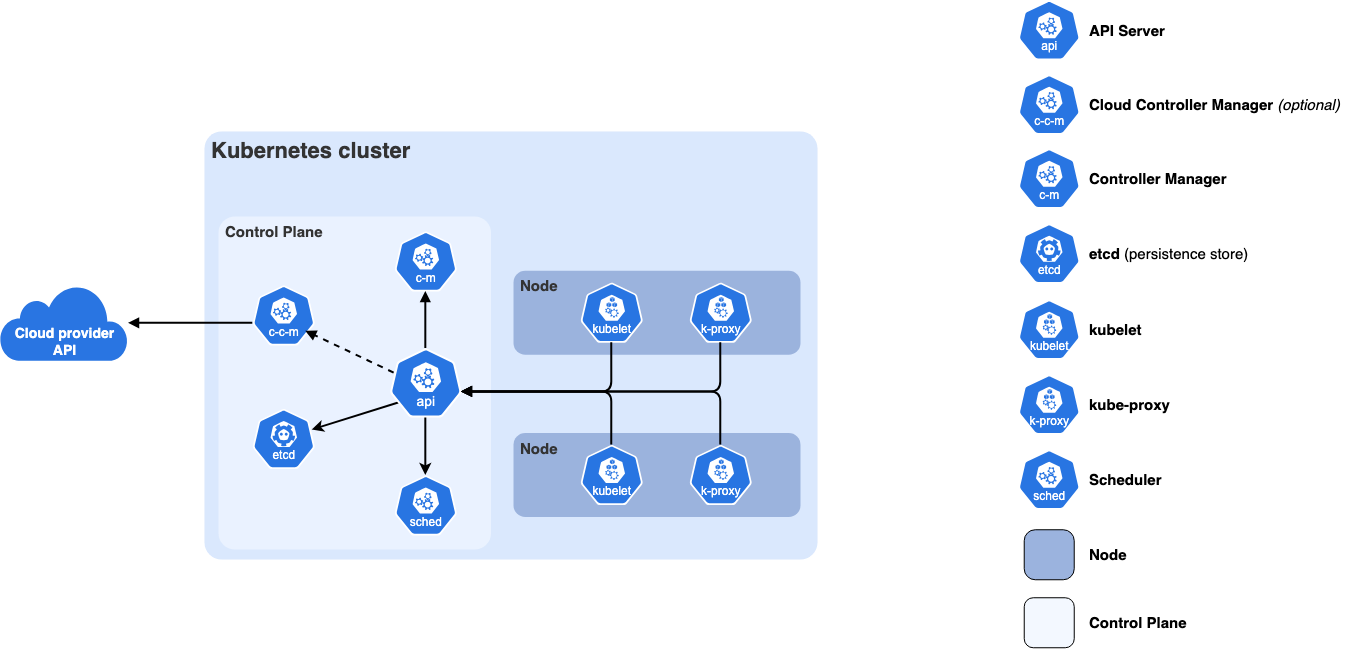
이전 글에서 봤던 실행 흐름은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
kubectl apply -f deployment.yaml
│
▼
API Server YAML을 받아 etcd에 저장
│
▼
Controller API Server를 watch → ReplicaSet 생성 → Pod 생성
│
▼
Scheduler API Server를 watch → Pod를 어느 Worker Node에서 실행할지 할당
│
▼
kubelet API Server를 watch → 할당된 Pod를 Worker Node에서 생성
여기까지 이해하면 다음 질문이 남는다.
“kubelet은 어떻게 Pod를 실제 컨테이너 프로세스로 만드는가?”
YAML은 텍스트다. 그런데 최종 결과는 노드 위에서 실행 중인 Linux 프로세스다.
1
2
3
4
5
6
7
8
9
10
11
image: ghcr.io/example:latest
# 이미지는 어디서 가져오고 어떻게 실행 가능한 rootfs가 되는가
resources:
limits:
cpu: "500m"
memory: "128Mi"
# 이 값은 어떤 커널 메커니즘으로 제한되는가
replicas: 3
# 누가 Pod 3개를 만들고 유지하는가
이 질문들은 한 레이어에서 답할 수 없다. 쿠버네티스 실행 경로는 여러 표준과 구현체가 층층이 연결된 구조다.
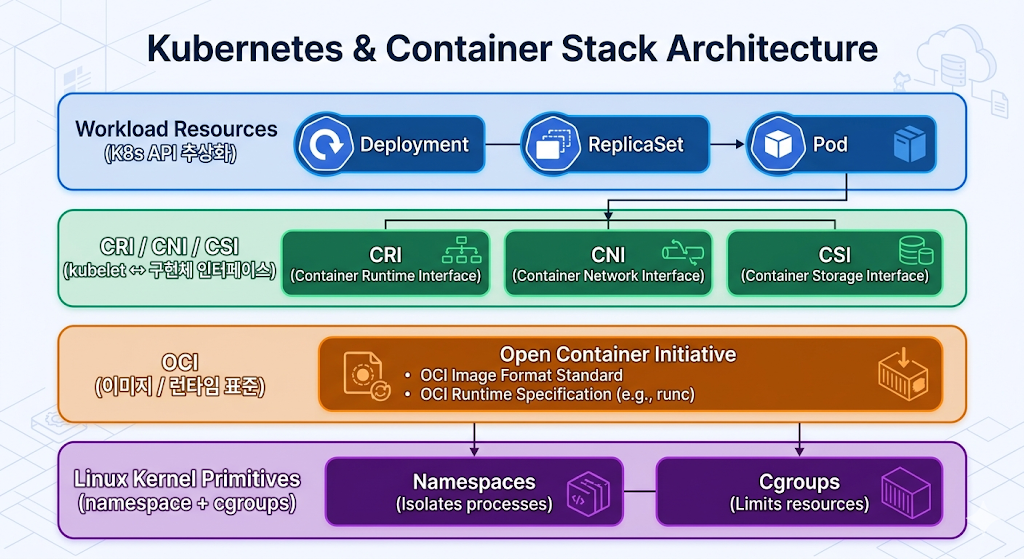
이번 글의 목표는 아래 그림의 각 연결선을 설명하는 것이다.

1. Linux Kernel Primitives
쿠버네티스가 컨테이너를 실행하려면 먼저 컨테이너가 무엇인지부터 정확히 봐야 한다.
컨테이너는 VM처럼 독립된 커널을 가진 실행 환경이 아니다. 컨테이너는 호스트 커널을 공유하되 namespace로 격리되고 cgroups로 제한된 프로세스 그룹이다.
1.1 ABI와 컨테이너가 커널을 공유할 수 있는 이유
프로그래밍 언어로 작성한 코드는 결국 하드웨어에서 실행되는 바이너리다. ABI(Application Binary Interface)는 두 소프트웨어 컴포넌트 사이의 인터페이스를 바이너리 수준에서 정의한다.
컨테이너를 이해할 때 핵심이 되는 ABI는 Syscall ABI다. 프로세스가 파일을 열고, 메모리를 할당하고, 네트워크 소켓을 만들 때 결국 Linux 커널에 syscall을 호출한다.
1
2
3
4
5
6
7
8
Application Code (Java, Python, Go, C ...)
↓
각 언어의 런타임 또는 glibc wrapper
↓
rax=번호, rdi/rsi/rdx/r10/r8/r9 설정
syscall 명령어 실행
↓
Linux Kernel
x86_64 Linux에서 syscall 호출 규약은 대략 다음과 같다.
1
2
3
4
5
6
7
8
9
10
rax ← syscall 번호
rdi ← 1번째 인자
rsi ← 2번째 인자
rdx ← 3번째 인자
r10 ← 4번째 인자
r8 ← 5번째 인자
r9 ← 6번째 인자
실행: syscall 명령어
반환: rax
Linux의 userspace syscall interface는 매우 안정적으로 유지된다. 그래서 컨테이너 이미지 안의 바이너리는 특정 커널 전체가 아니라 호환되는 Linux syscall ABI를 요구한다.

VM은 하이퍼바이저 위에 독립 커널을 올린다. 반면 컨테이너 안의 프로세스는 호스트 커널에 직접 syscall을 보낸다. 따라서 컨테이너는 VM보다 가볍지만, 호스트 커널과 다른 syscall ABI를 요구하는 워크로드는 실행할 수 없다.
| 상황 | 컨테이너가 부적합한 이유 |
|---|---|
| Linux 호스트에서 Windows 애플리케이션 실행 | syscall ABI가 다르다 |
| 최신 커널 syscall을 요구하는 앱을 구버전 커널에서 실행 | 호스트 커널에 해당 syscall이 없다 |
| 커널 모듈이나 드라이버 개발 | 컨테이너는 커널을 소유하지 않는다 |
| 강한 멀티테넌트 격리 필요 | 모든 컨테이너가 같은 커널 코드를 실행한다 |
1.2 namespace: 보이는 것의 격리
호스트 커널을 공유하면 기본적으로 모든 프로세스가 같은 PID 공간, 같은 네트워크 스택, 같은 파일시스템 뷰를 바라본다. namespace는 커널의 전역 서브시스템을 인스턴스 단위로 나눠 프로세스가 자신이 속한 인스턴스만 보게 만든다.
| 커널 서브시스템 | namespace | 분리 단위 |
|---|---|---|
| Process management | pid | 프로세스 ID 공간 |
| Network stack | net | 네트워크 인터페이스, IP, 라우팅, netfilter |
| VFS | mnt | 마운트 포인트 |
| System information | uts | hostname, domainname |
| IPC subsystem | ipc | System V IPC, POSIX message queue |
| Security / Credential | user | UID/GID 매핑 |
pid namespace를 예로 들면, 컨테이너 안의 첫 번째 프로세스는 PID 1로 보인다. 하지만 호스트에서는 다른 PID를 가진 일반 프로세스다.
1
2
3
4
5
호스트 PID 공간 컨테이너 pid namespace
────────────── ──────────────────────
PID 1 (systemd) PID 1 (nginx)
PID 2 (kthread) PID 2 (worker)
PID 847 (nginx) ──────────────────────────────→ 호스트에서 실제 PID는 847
namespace는 clone() syscall의 flag 조합으로 생성할 수 있다.
1
2
3
4
5
6
7
long clone(
unsigned long flags,
void *child_stack,
int *ptid,
int *ctid,
unsigned long newtls
);
| flags | namespace |
|---|---|
CLONE_NEWPID | pid namespace |
CLONE_NEWNET | net namespace |
CLONE_NEWNS | mnt namespace |
CLONE_NEWUTS | uts namespace |
CLONE_NEWIPC | ipc namespace |
CLONE_NEWUSER | user namespace |
CLONE_NEWCGROUP | cgroup namespace |
clone() flag 조합에 따라 프로세스, 스레드, 컨테이너가 모두 만들어진다.
1
2
3
4
5
6
7
8
clone(SIGCHLD)
→ 프로세스 생성
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_THREAD ...)
→ 스레드 생성
clone(CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC)
→ 컨테이너처럼 격리된 프로세스 생성
커널 수준에서 세 개념은 전혀 별개의 마법이 아니다. 무엇을 공유하고 무엇을 분리하는지의 차이다.
1.3 cgroups: 사용할 수 있는 양의 제한
namespace가 “무엇이 보이는가”를 제어한다면, cgroups(Control Groups)는 “얼마나 사용할 수 있는가”를 제어한다.
| cgroup 서브시스템 | 제한 대상 | Kubernetes 연결 |
|---|---|---|
| cpu | CPU 사용량 | resources.limits.cpu → cpu.max |
| memory | 메모리 상한 | resources.limits.memory → memory.max |
| blkio | 블록 디바이스 I/O | 스토리지 I/O 제한 |
| pids | 프로세스 수 상한 | fork bomb 방지 |
cgroups는 계층 구조를 가진다.
1
2
3
4
5
6
7
root cgroup (노드 전체 자원)
└── kubepods
├── pod-abc123
│ ├── container-nginx cpu: 500m, memory: 128Mi
│ └── container-sidecar cpu: 100m, memory: 64Mi
└── pod-def456
└── container-app
cgroups v2에서는 /sys/fs/cgroup 아래의 파일을 읽고 쓰는 방식으로 자원 제한을 설정한다.
1
2
3
4
5
6
7
8
# cgroups v2: 단일 디렉토리에 모든 컨트롤러 통합
mkdir /sys/fs/cgroup/container-nginx
# 메모리 상한 설정 (128Mi = 134217728 bytes)
echo "134217728" > /sys/fs/cgroup/container-nginx/memory.max
# 프로세스를 이 cgroup에 등록
echo <PID> > /sys/fs/cgroup/container-nginx/cgroup.procs
CPU limit은 CFS quota로 적용된다.
1
2
# 500m 설정: 100ms 주기 중 50ms만 사용 가능
echo "50000 100000" > /sys/fs/cgroup/container-nginx/cpu.max
CPU는 quota를 초과하면 다음 period까지 실행이 중단된다. 즉 종료가 아니라 스로틀링(throttling)이다.
반면 메모리는 압축할 수 없다. memory.max에 도달하면 커널은 먼저 page cache 회수와 swap out을 시도하고, 실패하면 OOM killer가 해당 cgroup 안의 프로세스를 종료한다.
1
2
3
4
5
6
7
8
9
10
11
12
메모리 사용량 >= memory.max
↓
커널: 메모리 회수 시도
├── page cache 반환
└── inactive 페이지 swap out
│
├── 회수 성공 → 정상 동작 계속
└── 회수 실패 → OOM killer 발동
↓
해당 cgroup 내 프로세스 종료
↓
K8s Pod 상태: OOMKilled
1.4 pivot_root(): 컨테이너의 / 만들기
mnt namespace는 마운트 포인트 뷰를 분리하지만, 새 mnt namespace를 만들었다고 해서 프로세스의 /가 자동으로 컨테이너 이미지의 rootfs가 되는 것은 아니다.
1
2
3
4
5
mnt namespace 생성 직후
컨테이너 프로세스의 / → 호스트의 /
pivot_root() 호출 이후
컨테이너 프로세스의 / → OCI 이미지 rootfs
pivot_root()는 현재 프로세스의 루트 파일시스템을 교체하는 syscall이다.
1
2
3
4
#include <sys/syscall.h>
#include <unistd.h>
syscall(SYS_pivot_root, new_root, put_old);
컨테이너 런타임은 보통 다음 순서로 rootfs를 구성한다.
1
2
3
4
5
6
7
8
9
OCI 이미지 레이어 (lowerdir)
↓
OverlayFS 마운트
(lowerdir + upperdir)
↓
pivot_root
↓
컨테이너 프로세스
/ → OCI 이미지 기반 rootfs
1.5 namespace와 cgroups만으로 부족한 것
namespace와 cgroups만으로 완전한 컨테이너 환경이 만들어지는 것은 아니다.
| 구성 요소 | namespace/cgroups로 안 되는 이유 | 담당 레이어 |
|---|---|---|
| rootfs | mnt namespace는 뷰만 분리. 실제 / 변경은 별도 syscall 필요 | OCI runtime |
| 네트워크 | net namespace는 빈 네트워크 스택만 생성 | CNI |
| capabilities | UID 매핑과 별개로 커널 권한 세분화 필요 | 보안 설정 |
| seccomp | 호출 가능한 syscall 자체를 제한해야 함 | 보안 설정 |
| AppArmor/SELinux | MAC 정책 필요 | 보안 설정 |
컨테이너 런타임은 이 기능들을 조합해 프로세스를 실행한다. 이 조합의 입력 형식을 표준화한 것이 OCI Runtime Spec이다.
2. OCI: 이미지와 컨테이너 실행의 표준화
OCI(Open Container Initiative)는 Docker의 이미지 포맷과 런타임 동작 방식이 특정 구현체에 종속되는 문제를 해결하기 위해 만들어진 표준이다.
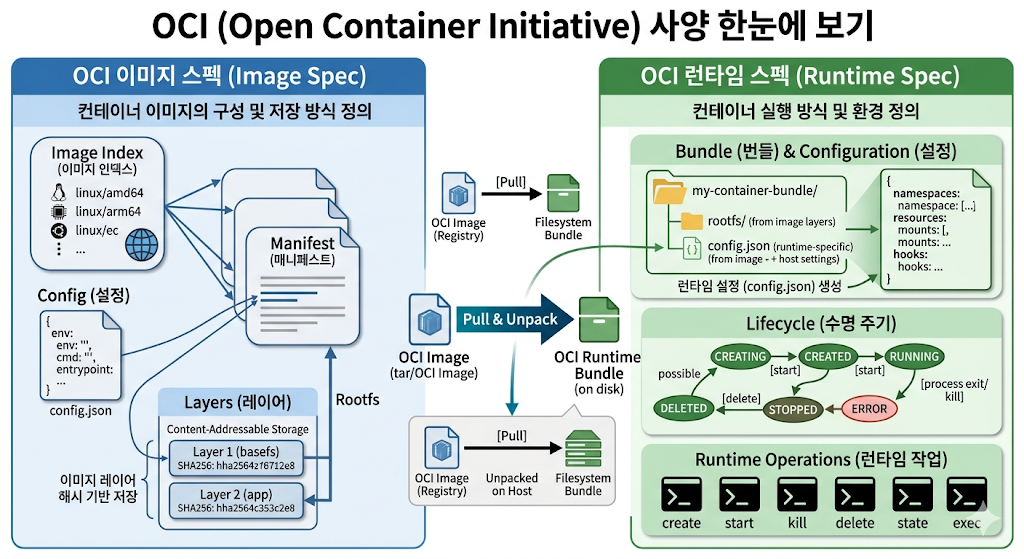
OCI는 크게 세 영역을 다룬다.
| Spec | 담당 범위 |
|---|---|
| Distribution Spec | 레지스트리 API 프로토콜, 이미지 push/pull HTTP 통신 |
| Image Spec | 이미지 포맷, Manifest / Configuration / Layers 구조 |
| Runtime Spec | Bundle 포맷, 컨테이너 생명주기, 표준 동작 |
2.1 Docker 이미지에서 OCI 이미지로
Dockerfile을 작성하면 각 명령은 이미지 레이어가 된다.
1
2
3
4
FROM ubuntu:22.04
RUN apt-get update && apt-get install -y nginx
COPY ./config /etc/nginx
CMD ["/bin/nginx", "-g", "daemon off;"]
1
2
3
FROM ubuntu:22.04 ← Layer 1: ubuntu base
RUN apt-get install nginx ← Layer 2: nginx 설치 결과
COPY ./config /etc/nginx ← Layer 3: config 파일 추가
각 레이어는 이전 레이어 대비 변경분(changeset)만 기록한다. 컨테이너 실행 시에는 읽기 전용 이미지 레이어 위에 쓰기 가능한 레이어가 추가된다.
1
2
3
4
5
6
7
8
컨테이너 실행 시
─────────────────────────────
upperdir (쓰기 가능) ← 실행 중 변경분
─────────────────────────────
Layer 3: config 파일
Layer 2: nginx 바이너리
Layer 1: ubuntu base ← 읽기 전용
─────────────────────────────
이미지는 실행 중인 프로세스가 아니다. 파일시스템 레이어와 실행 파라미터를 패키징한 읽기 전용 템플릿이다.
2.2 OCI Image Spec
OCI Image Spec은 이미지를 Index, Manifest, Configuration, Layers로 나눠 정의한다.
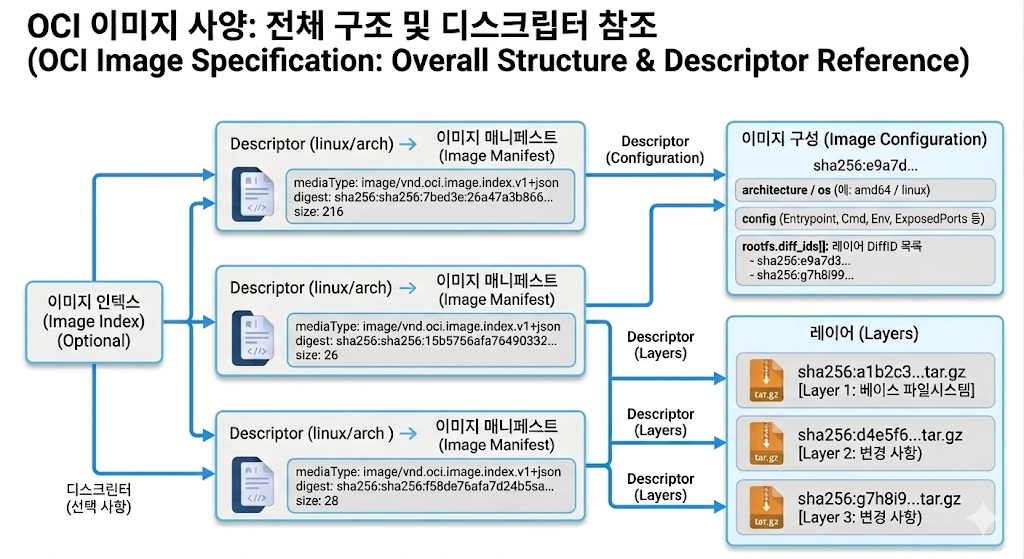
이 구조는 세 가지 문제를 해결한다.
| 문제 | 해결 방식 |
|---|---|
| multi-architecture | Image Index가 플랫폼별 Manifest를 가리킨다 |
| 실행 가능성 | Image Configuration이 Entrypoint, Cmd, Env, rootfs 정보를 담는다 |
| 무결성 | Descriptor의 digest로 하위 컴포넌트를 참조하고 검증한다 |
Descriptor는 OCI Image Spec의 기본 참조 구조다.
1
2
3
4
5
{
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"digest": "sha256:a1b1c3...",
"size": 7682
}
| field | 역할 |
|---|---|
mediaType | 참조 대상이 Manifest인지 Config인지 Layer인지 구분 |
digest | 참조 대상의 SHA256 해시 |
size | 바이트 크기, 다운로드 검증에 사용 |
digest는 파일 안에 저장된 값이 아니라 파일 내용으로부터 계산되는 값이다.
1
2
3
4
5
6
7
8
9
상위 문서가 하위 문서의 digest를 가진다
↓
digest를 registry request URL에 넣어 요청한다
↓
파일을 받는다
↓
받은 파일 내용으로 SHA256을 계산한다
↓
계산값이 상위 문서의 digest와 일치하면 신뢰한다
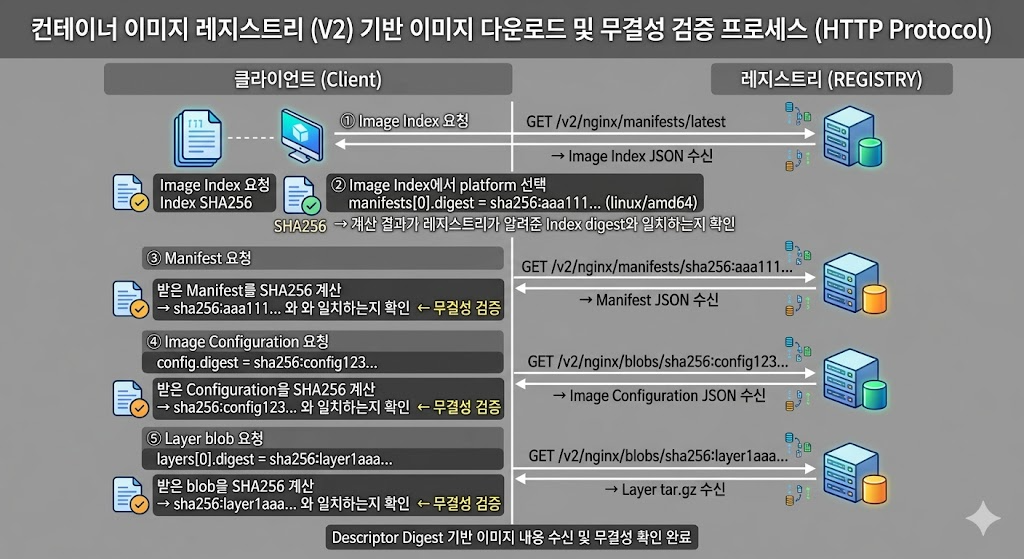
레이어는 전송 시 압축된 tar.gz blob이고, 로컬에서는 압축 해제된 tar changeset이다. 그래서 두 종류의 해시가 존재한다.
| 해시 종류 | 계산 대상 | 위치 |
|---|---|---|
manifest.layers[].digest | 압축된 blob(tar.gz) | Image Manifest |
config.rootfs.diff_ids[] | 압축 해제된 tar | Image Configuration |
1
2
3
4
5
6
7
8
9
10
11
레지스트리에서 tar.gz 수신
↓
manifest.layers[].digest 검증
↓
gzip 압축 해제 → tar
↓
SHA256(tar) 계산
↓
config.rootfs.diff_ids[]와 비교
↓
OverlayFS lowerdir로 적재
2.3 OCI Runtime Spec과 Bundle
Image Spec의 결과물은 곧바로 runtime에 들어가지 않는다. 먼저 OCI Runtime Bundle로 변환된다.
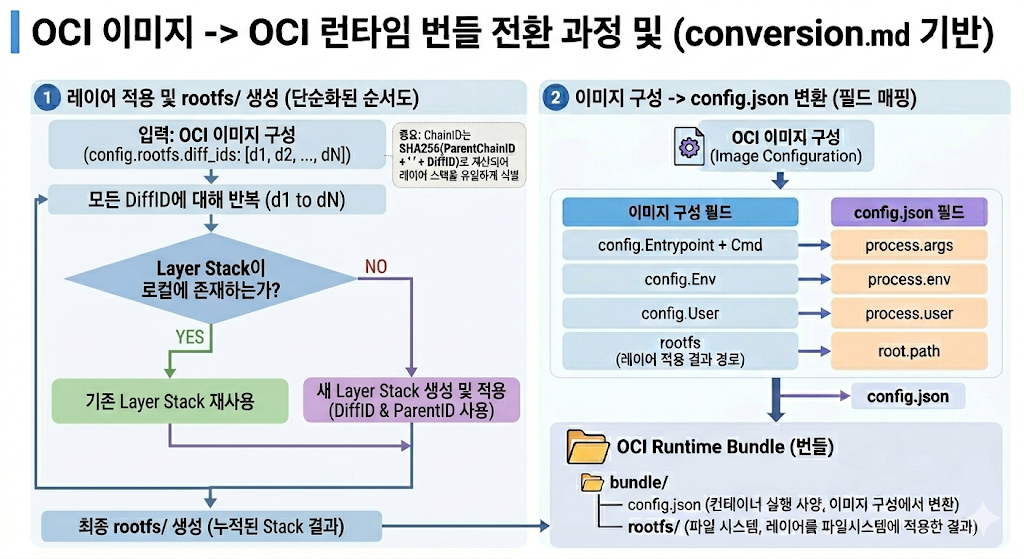
1
2
3
bundle/
├── config.json ← Image Configuration에서 변환된 컨테이너 실행 사양
└── rootfs/ ← Layers를 파일시스템에 적용한 결과
이 변환을 수행하는 주체를 converter라고 부른다. containerd, CRI-O 같은 high-level runtime이 converter 역할을 한다.
| Image Configuration | config.json field |
|---|---|
config.Entrypoint + config.Cmd | process.args |
config.Env | process.env |
config.User | process.user |
| rootfs 적용 결과 경로 | root.path |
config.json은 결국 kernel primitive 선언이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"ociVersion": "1.0.0",
"process": {
"args": ["/bin/nginx", "-g", "daemon off;"],
"env": ["PATH=/usr/local/sbin:/usr/local/bin"]
},
"root": {
"path": "rootfs"
},
"linux": {
"namespaces": [
{"type": "pid"},
{"type": "net"},
{"type": "mnt"},
{"type": "uts"},
{"type": "ipc"}
],
"cgroupsPath": "/kubepods/pod-abc123/container-nginx",
"resources": {
"cpu": {"quota": 50000, "period": 100000},
"memory": {"limit": 134217728}
}
}
}
config.json field | 실제 동작 | 커널 자원 |
|---|---|---|
linux.namespaces[] | clone() | namespace 생성 |
linux.resources.cpu | cgroupfs write | CFS quota |
linux.resources.memory | cgroupfs write | OOM killer 기준 |
root.path | pivot_root() | rootfs 교체 |
mounts[] | mount() | /proc, /dev, /sys 구성 |
process.args | execve() | user process 실행 |
2.4 OCI Runtime lifecycle
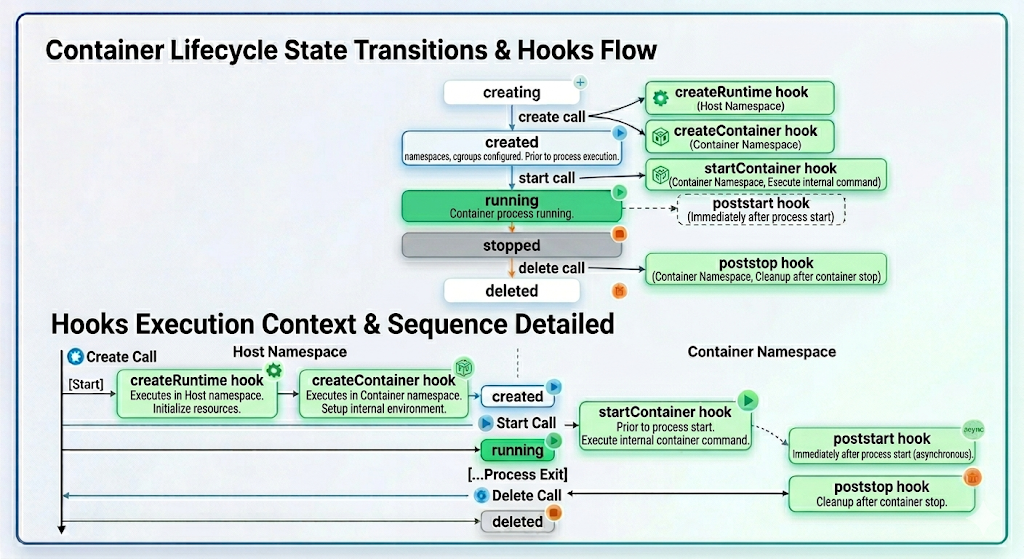
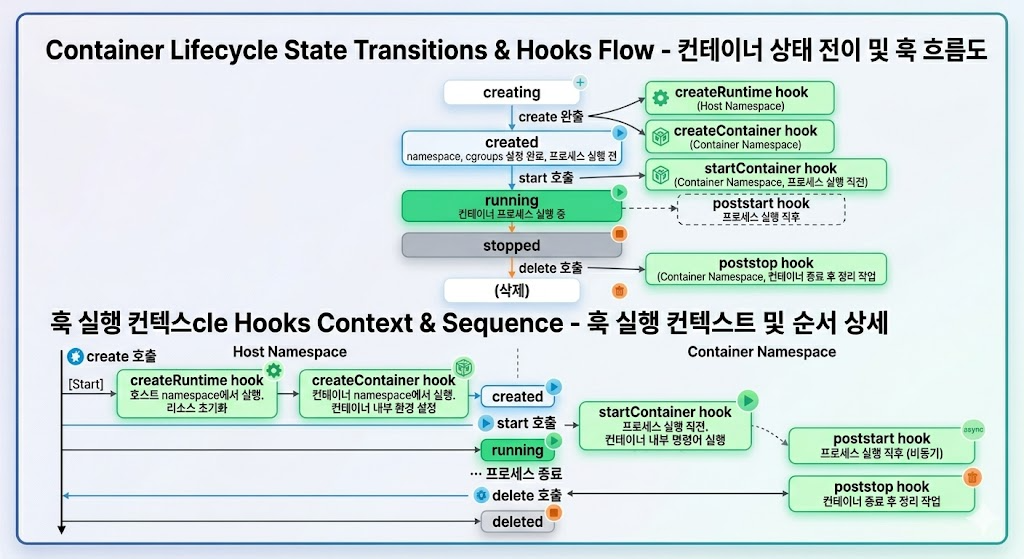
OCI Runtime Spec은 컨테이너 상태와 전이 동작도 표준화한다.
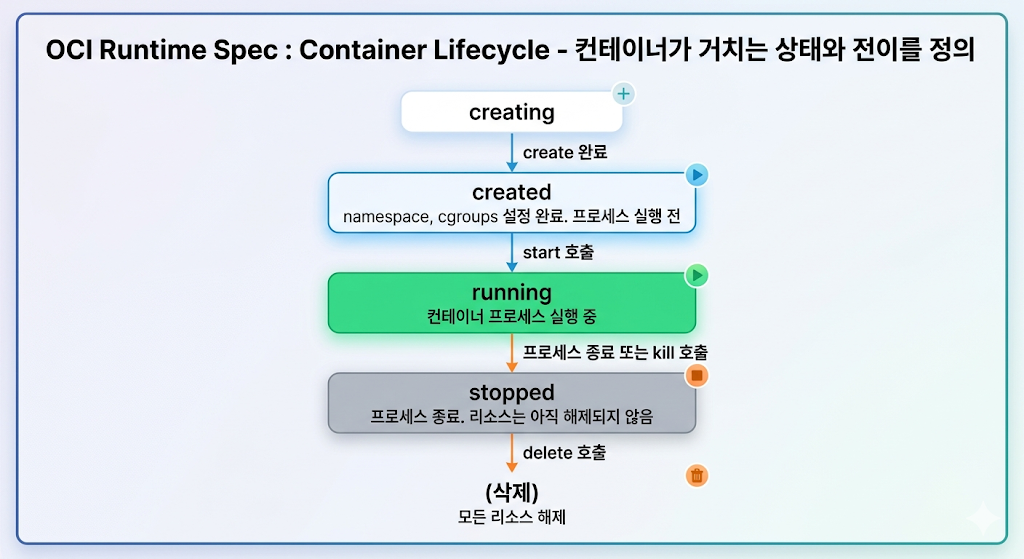
| 상태 | 의미 |
|---|---|
creating | 컨테이너 생성 중 |
created | 실행 환경 구성 완료, 프로세스 시작 전 |
running | 컨테이너 프로세스 실행 중 |
stopped | 프로세스 종료 |
| 동작 | 수행 내용 | 핵심 syscall |
|---|---|---|
create | namespace 생성, cgroups 설정, rootfs 교체 | clone(), cgroupfs write, pivot_root() |
start | 컨테이너 프로세스 실행 | execve() |
kill | 실행 중인 프로세스에 signal 전달 | kill() |
delete | cgroup 해제, rootfs unmount, namespace fd 정리 | umount2(), close() |
state | 컨테이너 상태 조회 | runtime별 구현 |
create와 start가 분리된 것은 중요하다. 실행 환경을 먼저 구성하고 검증한 뒤, 이상이 없을 때 프로세스를 시작할 수 있기 때문이다.
Lifecycle Hook은 각 상태 전이 시점에 실행되는 명령이다.
2.5 OCI 구현체
OCI Runtime Spec은 인터페이스를 정의할 뿐 구현 방식을 강제하지 않는다.
| 구현체 | 컨테이너 실행 방식 | 특징 |
|---|---|---|
| runc | Linux namespace + cgroups 직접 사용 | OCI reference 구현체 |
| gVisor(runsc) | syscall을 user-space kernel이 처리 | 호스트 커널 공격 표면 완화 |
| Kata Containers | 경량 VM + 독립 커널 | 강한 격리, 멀티테넌트 적합 |
1
2
3
4
5
동일한 Bundle 입력
│
├── runc → clone() + cgroupfs + pivot_root()
├── gVisor → user-space kernel
└── Kata → 경량 VM + 독립 커널
runtime 구현체는 달라도 Bundle과 lifecycle operation이 표준화되어 있으므로 상위 레이어는 같은 방식으로 다룰 수 있다.
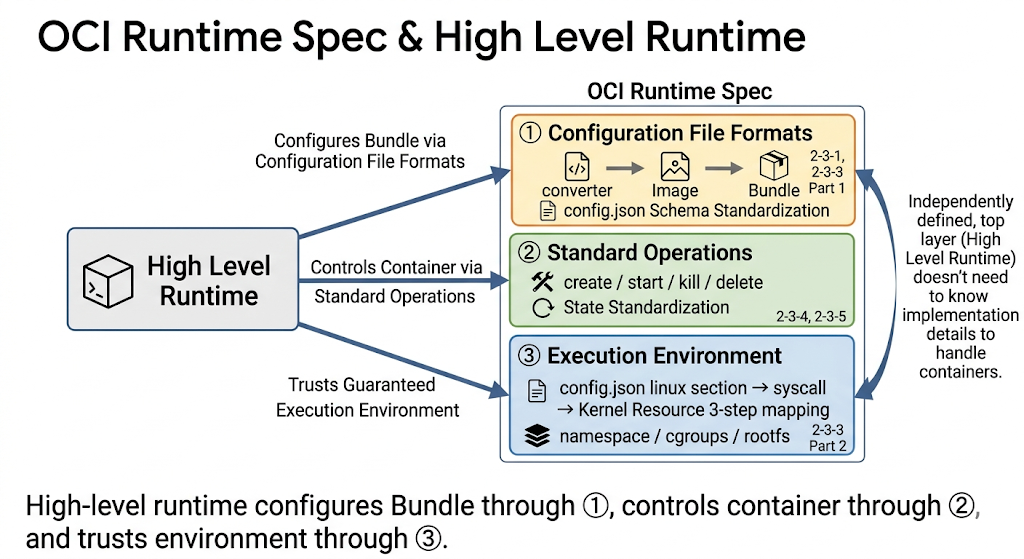
OCI의 핵심 원칙은 다음처럼 정리할 수 있다.
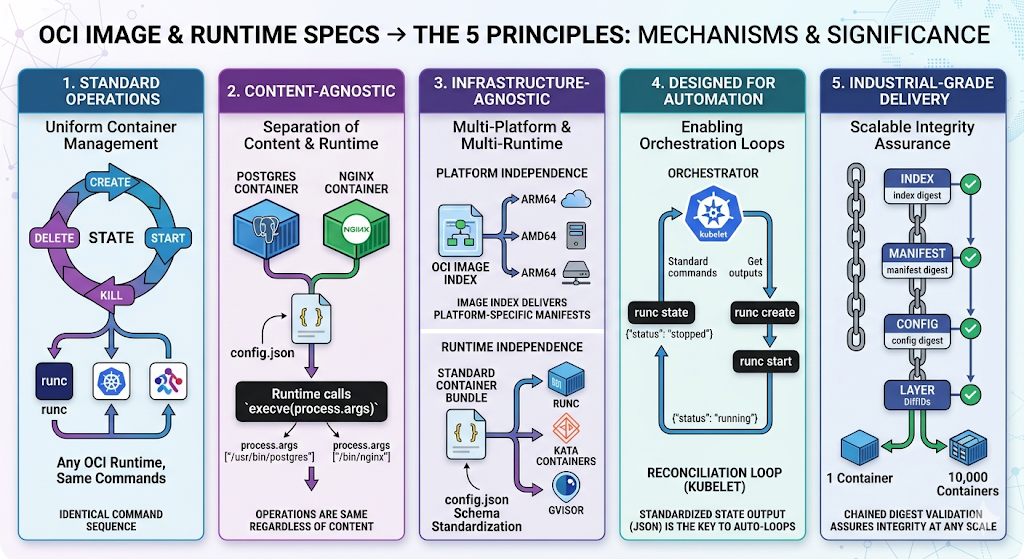
| 원칙 | 구현 메커니즘 |
|---|---|
| Standard operations | create, start, kill, delete, state |
| Content-agnostic | 내용물과 무관하게 process.args를 execve() |
| Infrastructure-agnostic | Image Index와 Runtime Spec으로 플랫폼/런타임 교체 가능 |
| Designed for automation | state 출력과 operation 표준화 |
| Industrial-grade delivery | digest chain 기반 무결성 검증 |
그러나 OCI만으로 Kubernetes Pod 실행은 완성되지 않는다.
3. CRI: kubelet과 runtime 사이의 Pod 인터페이스
OCI는 하나의 컨테이너를 실행하는 표준이다. Kubernetes는 Pod를 실행 단위로 삼는다. 이 차이를 메우는 인터페이스가 CRI(Container Runtime Interface)다.
3.1 Pod가 필요한 이유
실제 애플리케이션은 하나의 컨테이너만으로 구성되지 않는 경우가 많다.
예를 들어 애플리케이션 컨테이너가 로그를 파일로 쓰고, 로그 수집 sidecar가 그 파일을 읽어 Loki나 Elasticsearch로 전송한다고 하자. 두 프로세스를 한 컨테이너에 넣으면 애플리케이션 이미지와 로그 수집 에이전트의 배포 주기가 묶인다.
서비스 메시에서도 같은 문제가 있다. Envoy 같은 sidecar proxy는 애플리케이션의 모든 inbound/outbound 트래픽을 가로채야 하므로 애플리케이션과 동일한 network namespace를 봐야 한다.
따라서 sidecar 패턴은 다음 요구사항을 가진다.
- 서로 다른 이미지로 독립 배포되어야 한다.
- 필요에 따라 network namespace 또는 filesystem 일부를 공유해야 한다.
- 공유 namespace의 생명주기가 특정 애플리케이션 컨테이너에 종속되면 안 된다.
Pod는 이 요구사항을 만족하는 실행 단위다.
| namespace | Pod 내부 공유 여부 | 이유 |
|---|---|---|
| net | 공유 | 같은 IP, localhost 통신, sidecar proxy |
| ipc | 공유 | 컨테이너 간 IPC 객체 공유 |
| mnt | 독립 | 컨테이너별 rootfs 독립 |
| uts | 독립 | 컨테이너별 hostname 독립 |
| pid | 기본 독립 | shareProcessNamespace: true로 공유 가능 |
Pod 안의 모든 컨테이너는 같은 IP를 가지고 localhost로 통신한다. mnt namespace는 독립이지만 Volume을 통해 특정 디렉토리를 공유할 수 있다.
3.2 OCI가 다루지 않는 공백
OCI는 이미지와 단일 컨테이너 실행 파이프라인을 표준화했다.
1
Distribution Spec → Image Spec → Runtime Bundle → Runtime Spec
하지만 Kubernetes 입장에서는 공백이 있다.
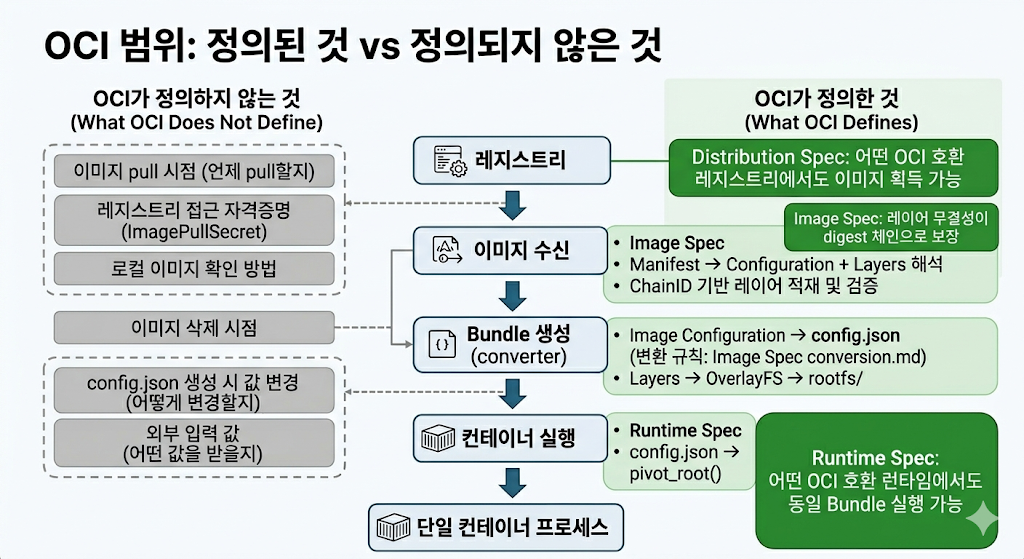
| 공백 | 설명 |
|---|---|
| 이미지 관리 주체 | 이미지를 언제 pull할지, 어떤 credential을 쓸지, 캐시를 어떻게 관리할지 OCI는 정하지 않는다 |
| converter 주체 | Image를 Bundle로 누가 언제 변환할지 정하지 않는다 |
| daemon 관리 | runc는 CLI 도구라 operation마다 실행되고 종료된다 |
| Pod 단위 조율 | 여러 컨테이너의 namespace 공유와 생명주기를 조율하지 않는다 |
CRI 구현체는 이 공백을 채우는 daemon runtime process다. containerd와 CRI-O가 대표적이다.
CRI 구현체는 다음 상태를 지속적으로 관리해야 한다.
- 이미지 레이어 목록
- ChainID 기반 레이어 관계
- 레이어 참조 수와 garbage collection 기준
- 컨테이너 상태
- 비정상 종료 감지
- kubelet의 restartPolicy 실행 보조
이 상태는 여러 컨테이너가 동시에 접근하고 수정하는 공유 상태다. 따라서 매번 runc 프로세스를 새로 실행하는 CLI 방식만으로는 충분하지 않다.
3.3 kubelet과 runtime daemon의 통신
kubelet과 runtime daemon은 같은 노드에서 실행되는 별도 프로세스다. 둘은 CRI gRPC API로 통신한다.
1
2
3
4
5
kubelet
│ gRPC over Unix domain socket
│ /run/containerd/containerd.sock
▼
containerd (runtime daemon)
gRPC over Unix domain socket이 적합한 이유는 다음과 같다.
| 요구사항 | 이유 |
|---|---|
| 양방향 요청/응답 | kubelet이 생성, 상태 조회, 중지 요청을 반복한다 |
| 구조화된 메시지 | PodSpec, ContainerConfig 등 복잡한 데이터 전달 |
| 스키마 계약 | protobuf로 인터페이스를 강제한다 |
| 로컬 통신 최적화 | TCP 네트워크 스택을 거치지 않는다 |
CRI는 두 개의 gRPC 서비스로 구성된다.
| 서비스 | 역할 |
|---|---|
| RuntimeService | PodSandbox와 Container 생명주기 관리 |
| ImageService | 이미지 pull, 조회, 삭제 관리 |
RuntimeService는 다시 PodSandbox Interface와 Container Interface로 나눌 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
RuntimeService
├── PodSandbox Interface
│ ├── RunPodSandbox
│ ├── StopPodSandbox
│ ├── RemovePodSandbox
│ ├── PodSandboxStatus
│ └── ListPodSandbox
└── Container Interface
├── CreateContainer
├── StartContainer
├── StopContainer
├── RemoveContainer
├── ContainerStatus
└── ListContainers
ImageService
├── PullImage
├── RemoveImage
├── ListImages
└── ImageStatus
RuntimeService와 ImageService가 분리된 이유는 이미지 생명주기와 컨테이너 실행 생명주기가 독립적이기 때문이다. 이미지는 컨테이너 생성 전에 미리 pull될 수 있고, 컨테이너 삭제 후에도 캐시에 남을 수 있다.
3.4 PodSandbox와 pause 컨테이너
PodSandbox는 Pod의 namespace 그룹을 추상화한 CRI 개념이다. 실제 구현에서는 보통 pause container가 PodSandbox의 실체가 된다.
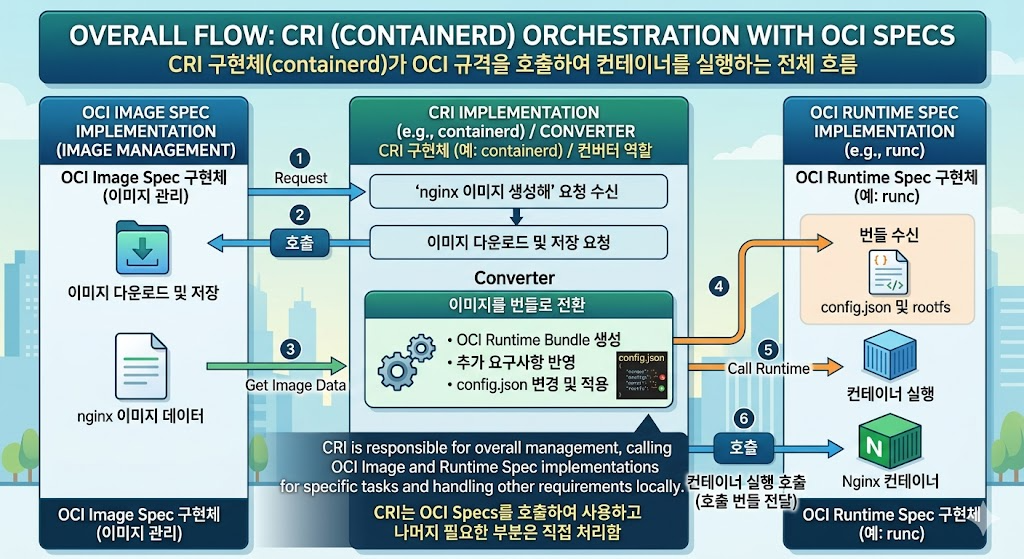
pause 컨테이너는 애플리케이션 로직 없이 namespace만 보유하는 컨테이너다.
1
2
3
int main() {
for (;;) pause(); // SIGTERM을 받을 때까지 대기
}
Pod 생성 시 kubelet은 먼저 PodSandbox를 만든다.
1
2
3
4
5
6
7
8
9
10
kubelet
│ RuntimeService.RunPodSandbox(PodSandboxConfig)
▼
containerd
├── pause 컨테이너 생성
│ clone(CLONE_NEWNET | CLONE_NEWIPC | ...)
│ → net / ipc namespace 생성 및 보유
├── CNI 호출
│ net namespace에 veth pair 연결, IP 할당
└── PodSandbox ID 반환
그 다음 애플리케이션 컨테이너는 PodSandbox ID를 참조해 만들어진다. CRI 구현체는 애플리케이션 컨테이너의 config.json을 생성할 때 pause 컨테이너의 namespace path를 주입한다.
1
2
3
4
5
6
7
8
9
10
{
"linux": {
"namespaces": [
{"type": "network", "path": "/proc/<pause-pid>/ns/net"},
{"type": "ipc", "path": "/proc/<pause-pid>/ns/ipc"},
{"type": "pid"},
{"type": "mnt"}
]
}
}
path가 있는 namespace는 새로 만들지 않고 기존 namespace에 합류한다. 이때 사용하는 syscall이 setns()다.
1
2
clone(CLONE_NEWNET) → 새 net namespace 생성 (pause 컨테이너)
setns(fd, CLONE_NEWNET) → 기존 net namespace 합류 (애플리케이션 컨테이너)
1
2
3
4
5
6
#include <sched.h>
int setns(
int fd,
int nstype
);
pause 컨테이너 구조 덕분에 애플리케이션 컨테이너가 crash 후 재시작되어도 Pod의 network namespace는 유지된다.
1
2
3
4
5
6
7
애플리케이션 컨테이너 A crash
↓
pause 컨테이너는 net namespace α 보유 중
↓
kubelet이 A 재시작
↓
새 A는 setns()로 동일한 net namespace α에 재합류
3.5 kubelet → CRI → OCI → kernel 전체 체인
Pod 생성 전체 흐름을 연결하면 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
1. kubelet이 Pod Spec 수신
API Server
│ Pod Spec 전달
▼
kubelet
│ ImageService.PullImage(image, authConfig)
▼
containerd
├── ImagePullSecret → 레지스트리 인증
├── Distribution Spec → 이미지 수신
├── Image Spec → Manifest / Layers digest 검증
└── ChainID 계산 → 레이어 재사용 또는 신규 적재
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2. RunPodSandbox
kubelet
│ RuntimeService.RunPodSandbox(PodSandboxConfig)
▼
containerd
├── pause 컨테이너 Bundle 생성
├── runc create / start
│ ├── clone(CLONE_NEWNET | CLONE_NEWIPC | ...)
│ ├── cgroupfs write
│ ├── pivot_root()
│ └── execve() → pause 프로세스 실행
├── CNI 호출
└── PodSandbox ID 반환
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
3. CreateContainer + StartContainer
kubelet
│ RuntimeService.CreateContainer(PodSandboxID, ContainerConfig)
▼
containerd
├── 애플리케이션 컨테이너 Bundle 생성
│ namespaces[].path = /proc/<pause-pid>/ns/net
└── Container ID 반환
kubelet
│ RuntimeService.StartContainer(ContainerID)
▼
containerd
└── runc create / start
├── setns(pause ns fd, CLONE_NEWNET)
├── setns(pause ns fd, CLONE_NEWIPC)
├── clone(CLONE_NEWPID | CLONE_NEWNS)
├── cgroupfs write
├── pivot_root()
└── execve() → 애플리케이션 프로세스 실행
레이어 전체 구조는 다음처럼 정리된다.
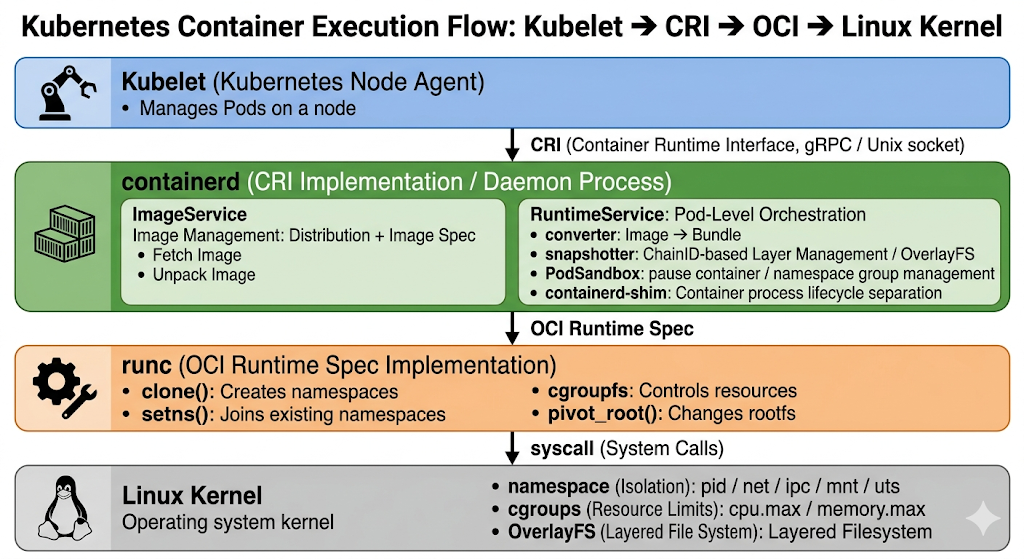
4. Pod 생명주기
섹션 3까지는 kubelet이 CRI 파이프라인을 호출해 컨테이너를 실행하는 흐름을 봤다. 하지만 kubelet의 역할은 실행에서 끝나지 않는다.
4.1 kubelet의 역할
kubelet은 각 Worker Node에서 실행되는 에이전트이며 다음 일을 한다.
| 역할 | 설명 |
|---|---|
| CRI 파이프라인 실행 | Pod Spec을 받아 RunPodSandbox / CreateContainer / StartContainer 호출 |
| Pod 생명주기 관리 | Probe, restartPolicy, container status 관리 |
| 노드 수준 자원 관리 | requests를 보고하고 limits를 cgroup에 적용 |
| API Server 상태 동기화 | Pod Phase, container state, probe 결과를 status에 반영 |
kubelet도 Reconciliation Loop로 동작한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
API Server watch
│ Pod Spec 수신 (desired state)
▼
실제 상태 조회
│ CRI RuntimeService.ListContainers
│ CRI RuntimeService.PodSandboxStatus
▼
상태 비교
├── 일치 → 아무것도 하지 않음
└── 불일치
├── Pod가 없음 → RunPodSandbox → CreateContainer → StartContainer
├── 컨테이너 crash → restartPolicy 확인 → 재시작
└── Pod 삭제 요청 → StopPodSandbox → RemovePodSandbox
4.2 Pod manifest 구조
Pod manifest는 여러 실행 레이어에 걸친 선언을 한 파일 안에 담는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
apiVersion: v1
kind: Pod
metadata:
name: example
namespace: default
labels:
app: example
spec:
containers:
- name: app
image: ghcr.io/example:latest
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 500m
memory: 1Gi
livenessProbe:
httpGet:
path: /health
port: 8080
readinessProbe:
httpGet:
path: /ready
port: 8080
env:
- name: ENV
value: production
ports:
- containerPort: 8080
restartPolicy: Always
volumes: []
| 필드 | 담당 레이어 |
|---|---|
image | CRI ImageService → Distribution / Image Spec |
resources | kubelet → cgroups |
livenessProbe / readinessProbe | kubelet 직접 관리 |
env | CRI converter → config.json process.env |
restartPolicy | kubelet Reconciliation Loop |
volumes | CSI |
4.3 requests, limits, QoS
resources.requests와 resources.limits는 비슷해 보이지만 역할이 다르다.
1
2
3
4
5
6
7
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 500m
memory: 1Gi
| 필드 | 사용하는 주체 | 의미 |
|---|---|---|
requests | Scheduler | 이 Pod를 배치하기 위해 예약해야 하는 자원 |
limits | kubelet / cgroups | 실제 사용 가능한 자원 상한 |
1
2
3
4
5
6
requests → Scheduler
"이 노드에 250m CPU, 512Mi 메모리 여유가 있는가"
limits → kubelet → cgroup
cpu.max = 50000 100000
memory.max = 1073741824
CPU limits 초과는 CFS quota에 의한 스로틀링이다. 메모리 limits 초과는 회수 실패 시 OOM killer로 이어진다.
kubelet은 requests와 limits 설정을 기반으로 Pod에 QoS 클래스를 부여한다.
| QoS 클래스 | 조건 | 퇴출 우선순위 |
|---|---|---|
| Guaranteed | 모든 컨테이너의 requests = limits | 가장 낮음 |
| Burstable | 일부 컨테이너의 requests < limits | 중간 |
| BestEffort | requests / limits 미설정 | 가장 높음 |
노드 메모리가 부족해지면 kubelet은 BestEffort → Burstable → Guaranteed 순서로 Pod를 퇴출한다.
4.4 Probe
kubelet은 컨테이너 상태를 세 가지 Probe로 확인한다.
| Probe | 질문 | 실패 시 동작 |
|---|---|---|
startupProbe | 초기화를 완료했는가 | 컨테이너 재시작 |
livenessProbe | 정상적으로 살아 있는가 | 컨테이너 재시작 |
readinessProbe | 트래픽을 받을 준비가 됐는가 | Service 엔드포인트에서 제거 |
Probe는 여러 방식으로 실행할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
httpGet:
path: /health
port: 8080
exec:
command:
- cat
- /tmp/healthy
tcpSocket:
port: 8080
grpc:
port: 8080
주요 파라미터는 다음과 같다.
1
2
3
4
5
6
7
8
9
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
| 파라미터 | 너무 작을 때 | 너무 클 때 |
|---|---|---|
initialDelaySeconds | 초기화 중인 컨테이너를 실패로 판단 | 실제 장애 감지 지연 |
periodSeconds | Probe 요청 부하 증가 | 장애 감지 지연 |
failureThreshold | 일시적 지연에도 재시작 | 장애 상태가 오래 지속 |
timeoutSeconds | 느린 응답을 실패로 판단 | 타임아웃 감지 지연 |
startupProbe가 설정되어 있으면 startupProbe가 성공하기 전까지 livenessProbe와 readinessProbe는 실행되지 않는다. Spring Boot처럼 초기화 시간이 긴 애플리케이션에서 livenessProbe의 initialDelaySeconds를 무리하게 키우지 않아도 되는 이유다.
4.5 restartPolicy와 Back-off
restartPolicy는 Pod 수준에서 설정되며 Pod 안의 모든 컨테이너에 적용된다.
| 정책 | 동작 | 적합한 워크로드 |
|---|---|---|
Always | 종료 이유와 무관하게 항상 재시작 | API 서버, 웹 서버 |
OnFailure | 비정상 종료일 때만 재시작 | 배치 작업 |
Never | 재시작하지 않음 | 일회성 작업 |
livenessProbe 실패나 프로세스 crash로 컨테이너를 재시작할 때도 pause 컨테이너는 유지된다.
1
2
3
4
5
6
7
8
9
10
11
livenessProbe 실패
↓
kubelet이 컨테이너 재시작 결정
↓
CRI StopContainer / RemoveContainer
↓
pause 컨테이너 유지 중
↓
CreateContainer(PodSandboxID)
↓
setns()로 같은 Pod namespace에 재합류
컨테이너가 반복적으로 실패하면 kubelet은 재시작 간격을 지수적으로 늘린다.
1
2
3
4
5
6
1회 실패 → 10초 후 재시작
2회 실패 → 20초 후 재시작
3회 실패 → 40초 후 재시작
4회 실패 → 80초 후 재시작
5회 실패 → 160초 후 재시작
6회 이상 → 300초 간격 유지
이 상태가 지속되면 CrashLoopBackOff로 보인다. 컨테이너가 영구히 죽은 상태가 아니라 kubelet이 다음 재시작을 기다리는 상태다.
4.6 Pod phase와 종료 시퀀스
Pod Phase는 Pod 전체 상태의 요약이다.
| Phase | 의미 |
|---|---|
Pending | API Server에 수락됐지만 컨테이너가 아직 실행되지 않음 |
Running | 노드에 바인딩됐고 최소 하나의 컨테이너가 실행 중 |
Succeeded | 모든 컨테이너가 정상 종료 |
Failed | 모든 컨테이너가 종료됐고 최소 하나가 비정상 종료 |
Unknown | kubelet과 통신 불가 |
각 컨테이너는 별도 상태를 가진다.
| 상태 | 의미 |
|---|---|
Waiting | 실행 중이 아님. 이미지 pull, 초기화 대기, CrashLoopBackOff 등 |
Running | 프로세스 실행 중 |
Terminated | 실행 완료. exitCode와 reason 기록 |
Pod 삭제 요청이 들어오면 kubelet은 graceful shutdown을 시도한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
kubectl delete pod 또는 Deployment 업데이트
↓
API Server → Pod에 deletionTimestamp 설정
↓
kubelet 감지
↓
SIGTERM 전달
↓
terminationGracePeriodSeconds 대기 (기본값 30초)
├── 프로세스 종료 → 정상 종료
└── 아직 실행 중 → SIGKILL
↓
StopPodSandbox → RemovePodSandbox
terminationGracePeriodSeconds가 애플리케이션의 실제 종료 시간보다 짧으면 SIGKILL로 강제 종료된다. 애플리케이션이 SIGTERM을 받아 graceful shutdown을 수행하도록 구현되어 있어야 이 메커니즘이 의미를 가진다.
5. Workload Resources
실제 운영 환경에서 Pod를 직접 선언하는 경우는 드물다. 보통 Deployment, StatefulSet, DaemonSet, Job 같은 Workload Resource가 Pod를 생성하고 유지한다.
1
2
3
4
5
6
7
Deployment / StatefulSet / DaemonSet / Job / CronJob
↓ 제어
ReplicaSet
↓ 제어
Pod
↓ 실행 요청
CRI
5.1 ReplicaSet
ReplicaSet은 선언된 수만큼 Pod를 유지한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
spec:
replicas: 3
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
- name: app
image: ghcr.io/example:latest
ReplicaSet Controller는 selector로 현재 Pod 수를 세고 replicas와 비교한다.
1
2
3
실행 중인 Pod 수 < replicas → Pod 생성
실행 중인 Pod 수 > replicas → Pod 삭제
실행 중인 Pod 수 = replicas → no-op
5.2 Deployment
Deployment는 ReplicaSet의 생성과 교체를 관리한다. 롤링 업데이트와 롤백을 제공한다.
1
2
3
4
5
6
7
8
9
10
11
12
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
spec:
containers:
- name: app
image: ghcr.io/example:v2
이미지 버전이 바뀌면 Deployment Controller는 새 ReplicaSet을 만들고 점진적으로 교체한다.
1
2
3
4
5
6
7
8
9
업데이트 전
ReplicaSet-v1 (replicas: 3) → Pod × 3
롤링 업데이트
ReplicaSet-v2 (replicas: 1) → Pod × 1 생성
ReplicaSet-v1 (replicas: 2) → Pod × 1 삭제
↓
ReplicaSet-v2 (replicas: 3)
ReplicaSet-v1 (replicas: 0, 롤백용 보존)
5.3 StatefulSet
StatefulSet은 상태가 있는 워크로드를 관리한다.
| 항목 | Deployment | StatefulSet |
|---|---|---|
| Pod 이름 | 랜덤 suffix | 고정 순서: app-0, app-1 |
| 네트워크 ID | 비고정 | Headless Service와 결합해 고정 |
| 스토리지 | 공유 가능 | Pod마다 독립 PVC 생성 |
| 시작 순서 | 무순서 | app-0 → app-1 → app-2 |
| 종료 순서 | 무순서 | app-2 → app-1 → app-0 |
데이터베이스 클러스터처럼 각 Pod의 정체성과 스토리지가 중요할 때 사용한다.
5.4 DaemonSet
DaemonSet은 모든 노드 또는 특정 노드에 Pod를 하나씩 배포한다.
1
2
노드 추가 → DaemonSet Controller가 해당 노드에 Pod 생성
노드 삭제 → 해당 노드의 Pod 자동 제거
대표적인 용도는 다음과 같다.
- 로그 수집기: Fluentd, Filebeat
- 모니터링 에이전트: Prometheus Node Exporter
- 네트워크 플러그인: Calico, Cilium
5.5 Job / CronJob
Job과 CronJob은 완료 기반 워크로드를 위한 리소스다.
| 리소스 | 실행 조건 | 종료 조건 | 용도 |
|---|---|---|---|
| Job | 즉시 실행 | 지정한 completions 수 달성 | 배치 처리, 마이그레이션 |
| CronJob | cron 표현식 스케줄 | Job과 동일 | 정기 백업, 리포트 생성 |
1
2
3
4
spec:
completions: 1
parallelism: 1
backoffLimit: 4
CronJob은 Job의 스케줄 버전이다.
1
2
3
4
5
6
7
8
9
spec:
schedule: "0 2 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: backup
image: backup-tool:latest
6. 마무리: YAML 필드 매핑
처음의 deployment.yaml로 돌아가면 각 필드가 닿는 레이어가 보인다.
| YAML 필드 | 레이어 | 메커니즘 |
|---|---|---|
spec.replicas | Workload Resources | ReplicaSet Controller가 Pod 수 제어 |
strategy.rollingUpdate | Workload Resources | Deployment Controller가 ReplicaSet 교체 |
containers[].image | CRI + OCI Image Spec | ImageService.PullImage → Distribution Spec → OverlayFS |
resources.requests | Scheduler | 노드 배치 결정 기준 |
resources.limits.cpu | Linux Kernel / cgroups | cpu.max → CFS quota |
resources.limits.memory | Linux Kernel / cgroups | memory.max → OOM killer |
livenessProbe | kubelet | 실패 시 컨테이너 재시작 |
readinessProbe | kubelet | 실패 시 Service endpoint 제거 |
envFrom.configMapRef | kubelet → CRI | converter → config.json process.env |
envFrom.secretRef | kubelet → CRI | converter → config.json process.env |
imagePullSecrets | CRI ImageService | PullImage AuthConfig → registry 인증 |
restartPolicy | kubelet | Reconciliation Loop → CRI 재시작 |
volumes | CSI | 스토리지 연결 |
전체 흐름은 다음처럼 정리된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
선언 (deployment.yaml)
↓ Controller
Workload Resources (Deployment / ReplicaSet)
↓ Pod Spec 등록
API Server / etcd
↓ kubelet watch
kubelet (Reconciliation Loop)
↓ CRI gRPC
containerd (daemon process)
├── ImageService : 이미지 pull / 캐시 관리
└── RuntimeService : Pod 수준 조율
├── PodSandbox : pause 컨테이너 / namespace 그룹
├── converter : Image → Bundle (config.json + rootfs/)
└── shim : 컨테이너 프로세스 생명주기
↓ OCI Runtime Spec
runc
├── clone() / setns() : namespace 생성 / 합류
├── cgroupfs : 자원 제한
└── pivot_root() : rootfs 교체
↓ syscall
Linux Kernel
├── namespace : 격리
├── cgroups : 자원 제한
└── OverlayFS : 레이어 파일시스템
쿠버네티스의 핵심은 모든 것을 직접 구현하는 데 있지 않다. 각 레이어가 자기 역할을 표준 인터페이스로 감추고, 위 레이어는 아래 레이어의 세부 구현을 몰라도 선언한 상태를 실제 프로세스로 수렴시킬 수 있게 만드는 데 있다.